
.svg)



Как мы ломали Glusterfs
История началась год назад, когда к нам пришел наш друг, коллега и большой эксперт по энтерпрайз стораджам со словами: «Парни, у меня тут завалялась шикарная хранилка со всеми модными фичами. 90Tb».

Особой необходимости мы в ней не видели, но, естественно, отказываться не стали. Настроили туда пару бекапов и на какое-то время благополучно забыли.
Что за Гластер, и зачем он нужен?
Это распределенная файловая система, которая давно дружит с Openstack и интегрирована в oVIrt/RHEV. Хоть наш IaaS и не на Openstack, у Гластера большое активное коммьюнити и есть нативная поддержка qemu в виде интерфейса libgfapi. Тем самым мы убиваем 2х зайцев:
1. Поднимаем сторадж для бекапов, полностью поддерживаемый нами. Больше не придется бояться в ожидании, когда вендор пришлет сломанную запчасть.
2. Тестируем новый тип хранения (volume type), который мы в перспективе можем предоставить нашим заказчикам.
Гипотезы, которые мы проверяли
- Что Гластер работает. Проверено.
- Что он отказоустойчив - можем ребутнуть любую ноду, и кластер продолжит работать, данные будут доступны. Можем ребутнуть несколько нод, данные не потеряются. Проверено.
- Что он надёжен – то есть не падает сам по себе, не истекает памятью и т.д. Частично верно, потребовалась много времени, чтобы понять, что проблема не в наших руках и головах, а в Striped конфигурации вольюма, который не смог работать стабильно ни в одной из собранных нами конфигураций (детали в конце).
Месяц ушёл на эксперименты и сборки разнообразных конфигураций и версий, потом была тестовая эксплуатация в продакшне как второй дестинейшн для наших технических бекапов. Мы хотели посмотреть, как он себя ведет полгода, прежде чем полностью положиться на него.
Как поднимали
Палок для экспериментов у нас хватало с излишком - стойка с Dell Poweredge r510 и пачка не очень шустрых SATA двухтерабайтников, оставшихся у нас по наследству от старого S3. Мы прикинули, что нам не нужно хранилище больше чем на 20тб и после этого нам понадобилось около получаса, чтобы набить в 2 стареньких Dell Power Edge r510 по 10 дисков, выбрать еще 1 сервер для роли арбитра, скачать пакетики и задеплоить его. Получилась вот такая схема.

Мы выбрали именно striped-replicated с арбитром, потому что это быстро (данные размазываются равномерно по нескольким брикам), достаточно надежно (реплика 2), можно пережить падение 1 ноды, не получив split-brain. Как же мы ошибались...
Главный минус нашего кластера в текущей конфигурации — это очень узкий канал - всего 1G, но для нашего назначения его вполне хватает. Поэтому данный пост не о тестировании скорости работы системы, а о её стабильности и том, что делать при авариях. Хотя в будущем мы планируем переключить его на Infiniband 56G с rdma и провести перформанс тесты, но это уже совсем другая история.
Глубоко вдаваться в процесс сборки кластера я не буду, здесь все достаточно просто:
Создаём директории для бриков:for i in {0..9} ; do mkdir -p /export/brick$i ; done Накатываем xfs на диски для бриков:
for i in {b..k} ; do mkfs.xfs /dev/sd$i ; done Добавляем точки монтирования в /etc/fstab:
/dev/sdb /export/brick0/ xfs defaults 0 0 /dev/sdc /export/brick1/ xfs defaults 0 0Монтируем:
/dev/sdd /export/brick2/ xfs defaults 0 0 /dev/sde /export/brick3/ xfs defaults 0 0
/dev/sdf /export/brick4/ xfs defaults 0 0 /dev/sdg /export/brick5/ xfs defaults 0 0
/dev/sdh /export/brick6/ xfs defaults 0 0 /dev/sdi /export/brick7/ xfs defaults 0 0
/dev/sdj /export/brick8/ xfs defaults 0 0 /dev/sdk /export/brick9/ xfs defaults 0 0
mount -a
Добавляем в брики директорию для вольюма, который будет называться holodilnik:
for i in {0..9} ; do mkdir -p /export/brick$i/holodilnik ; done Дальше нам надо спирить хосты кластера и создать вольюм.
Ставим пакеты на всех трёх хостах:
pdsh -w server[1-3] -- yum install glusterfs-server -y
Запускаем Гластер:
systemctl enable glusterd systemctl start glusterd
Полезно знать, что процессов у Гластера несколько, вот их назначения:
glusterd = management daemon Главный демон, управляет вольюмом, тянет за собой остальные демоны, отвечающие за брики и восстановление данных.
glusterfsd = per-brick daemon У каждого брика запускает свой glusterfsd демон.
glustershd = self-heal daemon Отвечает за ребилд данных у реплицированных
вольюмов в случаях отвала нод кластера. glusterfs = usually client-side, but also NFS on servers Например, прилетает с пакетом нативного клиента glusterfs-fuse.
Пирим ноды:
gluster peer probe server2 gluster peer probe server3
Собираем вольюм, здесь важен порядок бриков — реплицируемые брики идут следом друг за другом:
gluster volume create holodilnik stripe 10 replica 3 arbiter 1 transport tcp server1:/export/brick0/holodilnik server2:/export/brick0/holodilnik
server3:/export/brick0/holodilnik server1:/export/brick1/holodilnik
server2:/export/brick1/holodilnik server3:/export/brick1/holodilnik
server1:/export/brick2/holodilnik server2:/export/brick2/holodilnik
server3:/export/brick2/holodilnik server1:/export/brick3/holodilnik
server2:/export/brick3/holodilnik server3:/export/brick3/holodilnik
server1:/export/brick4/holodilnik server2:/export/brick4/holodilnik server3:/export/brick4/holodilnik server1:/export/brick5/holodilnik
server2:/export/brick5/holodilnik server3:/export/brick5/holodilnik server1:/export/brick6/holodilnik server2:/export/brick6/holodilnik
server3:/export/brick6/holodilnik server1:/export/brick7/holodilnik server2:/export/brick7/holodilnik server3:/export/brick7/holodilnik
server1:/export/brick8/holodilnik server2:/export/brick8/holodilnik server3:/export/brick8/holodilnik server1:/export/brick9/holodilnik
server2:/export/brick9/holodilnik server3:/export/brick9/holodilnik force
Нам пришлось перепробовать большое количество комбинаций параметров, версий ядра (3.10.0, 4.5.4) и самого Glusterfs (3.8, 3.10, 3.13), чтобы Гластер начал вести себя стабильно.
Также мы опытным путём выставили следующие значения параметров:
gluster volume set holodilnik performance.write-behind on gluster volume set holodilnik nfs.disable on gluster volume set holodilnik cluster.lookup-optimize off gluster volume set holodilnik performance.stat-prefetch off gluster volume set holodilnik server.allow-insecure on gluster volume set holodilnik storage.batch-fsync-delay-usec 0 gluster volume set holodilnik performance.client-io-threads off gluster volume set holodilnik network.frame-timeout 60 gluster volume set holodilnik performance.quick-read on gluster volume set holodilnik performance.flush-behind off gluster volume set holodilnik performance.io-cache off gluster volume set holodilnik performance.read-ahead off gluster volume set holodilnik performance.cache-size 0 gluster volume set holodilnik performance.io-thread-count 64 gluster volume set holodilnik performance.high-prio-threads 64 gluster volume set holodilnik performance.normal-prio-threads 64 gluster volume set holodilnik network.ping-timeout 5 gluster volume set holodilnik server.event-threads 16 gluster volume set holodilnik client.event-threads 16Дополнительные полезные параметры:
sysctl vm.swappiness=0 sysctl vm.vfs_cache_pressure=120 sysctl vm.dirty_ratio=5 echo "deadline" > /sys/block/sd[b-k]/queue/scheduler echo "256" > /sys/block/sd[b-k]/queue/nr_requests echo "16" > /proc/sys/vm/page-cluster blockdev --setra 4096 /dev/sd[b-k]Стоит добавить, что эти параметры хороши в нашем случае с бекапами, а именно с линейными операциями. Для рандомных кейсов чтения/записи надо подбирать что-нибудь другое.
Теперь мы рассмотрим плюсы и минусы разных типов подключения к Гластеру и результаты негативных тест-кейсов. Для подключения к вольюму мы протестировали все основные варианты:
1. Gluster Native Client (glusterfs-fuse) с параметром backupvolfile-server.
Минусы: — установка дополнительного софта на клиенты; — скорость. Плюс/минус: — долгая недоступность данных в случае отвала одной из нод кластера. Проблема правится параметром network.ping-timeout на стороне сервера. Выставив параметр в 5, шара отваливается, соответственно, на 5 секунд. Плюс: — достаточно стабильно работает, не наблюдалось массовых проблем с битыми файлами.2. Gluster Native Client (gluster-fuse) + VRRP (keepalived). Настроили переезжающий IP между двумя нодами кластера и гасили одну из них.
Минус: — установка дополнительного софта.Плюс: — конфигурируемый таймаут при переключении в случае отвала ноды кластера. Как оказалось, указание параметра backupvolfile-server или настройка keepalived необязательны, клиент сам подключается к демону Гластера (неважно, по какому из адресов), узнаёт остальные адреса и запускает запись на все ноды кластера. В нашем случае мы видели симметричный трафик с клиента на server1 и server2. Даже если вы указываете ему VIP-адрес, клиент всё равно будет использовать кластерные адреса Glusterfs. Мы пришли к выводу, что данный параметр полезен в том случае, когда клиент при старте пытается подключиться к Glusterfs-серверу, который недоступен, тогда он следом обратится к хосту, указанному в backupvolfile-server.
Комментарий из официальной документации:
The FUSE client allows the mount to happen with a GlusterFS “round robin” style connection. In /etc/fstab, the name of one node is used; however, internal mechanisms allow that node to fail, and the clients will roll over to other connected nodes in the trusted storage pool. The performance is slightly slower than the NFS method based on tests, but not drastically so. The gain is automatic HA client failover, which is typically worth the effect on performance.
3. NFS-Ganesha server, с Pacemaker.
Рекомендованный тип подключения, если по каким-то причинам вам не хочется использовать нативный клиент. Минусы: — ещё больше дополнительного софта; — возня с pacemaker; — отловили багу.
4. NFSv3 и NLM + VRRP (keepalived). Классический NFS с поддержкой локов и переезжающий IP между двумя нодами кластера.
Плюсы: — быстрое переключение в случае выхода из строя ноды; — простота настройки keepalived; — nfs-utils установлен на всех наших клиентских хостах по умолчанию. Минусы: — повисание NFS клиента в статусе D после нескольких минут rsync в точку монтирования; — падение ноды с клиентом целиком — BUG: soft lockup - CPU stuck for Xs! — отловили множество случаев, когда файлы ломались с ошибками stale file handle, Directory not empty при rm -rf, Remote I/O error и т. д. Самый худший вариант, более того, в поздних версиях Glusterfs он стал deprecated, никому не советуем. В итоге мы выбрали glusterfs-fuse без keepalived и с backupvolfile-server-параметром. Так как в нашей конфигурации он единственный показал стабильность, несмотря на относительно низкую скорость работы. Помимо необходимости в настройке высокодоступного решения, в продуктивной эксплуатации мы должны уметь восстанавливать работу сервиса в случае аварий. Поэтому после сборки стабильно работающего кластера мы приступили к деструктивным тестам.
Нештатное выключение ноды (cold reboot)
Мы запустили rsync большого количества файлов с одного клиента, жёстко погасили одну из нод кластера и получили очень забавные результаты. После падения ноды сначала запись остановилась на 5 секунд (за это отвечает параметр network.ping-timeout 5), после этого скорость записи в шару выросла вдвое, так как клиент больше не может реплицировать данные и начинает слать весь трафик на оставшуюся ноду, продолжая упираться в наш 1G канал.
Когда сервер загрузился, начался автоматический процесс лечения данных в кластере, за который отвечает демон glustershd, и скорость значительно просела. Так можно посмотреть количество файлов, которые лечатся после отвала ноды:
gluster volume heal holodilnik info
Brick server2:/export/brick1/holodilnik /2018-01-20-weekly/billing.tar.gz Status: Connected Number of entries: 1 Brick server2:/export/brick5/holodilnik /2018-01-27-weekly/billing.tar.gz Status: Connected Number of entries: 1 Brick server3:/export/brick5/holodilnik /2018-01-27-weekly/billing.tar.gz Status: Connected Number of entries: 1 ...
По окончании лечения счётчики обнулились и скорость записи вернулась к прежним показателям.
Отвал диска и его замена
Отвал диска с бриком, так же, как и его замена, никак не замедлил скорость записи в шару. Вероятно, дело в том, что узкое место тут, опять же, канал между нодами кластера, а не скорость дисков. Как только у нас появятся дополнительные карты Infiniband, мы проведём тесты с более широким каналом. Хочется отметить, что, когда вы меняете вылетевший диск, он должен вернуться с тем же именем в sysfs (/dev/sdX). Часто происходит, что новому диску присваивается следующая буква. Я крайне не рекомендую вводить его в таком виде, так как при последующей перезагрузке он возьмёт старое название, имена блочных девайсов съедут и брики не поднимутся. Поэтому придётся провести несколько действий. Скорее всего, проблема в том, что где-то в системе остались точки монтирования вылетевшего диска. Поэтому делаемumount. umount /dev/sdX
Также проверяем, какой процесс может держать этот девайс:
lsof | grep sdXИ останавливаем этот процесс. После этого надо сделать рескан. Смотрим в
dmesg-Hболее подробную информацию о расположении вылетевшего диска:
[Feb14 12:28] quiet_error: 29686 callbacks suppressed [ +0.000005] Buffer I/O error on device sdf, logical block 122060815 [ +0.000042] lost page write due to I/O error on sdf [ +0.001007] blk_update_request: I/O error, dev sdf, sector 1952988564 [ +0.000043] XFS (sdf): metadata I/O error: block 0x74683d94 ("xlog_iodone") error 5 numblks 64 [ +0.000074] XFS (sdf): xfs_do_force_shutdown(0x2) called from line 1180 of file fs/xfs/xfs_log.c. Return address = 0xffffffffa031bbbe [ +0.000026] XFS (sdf): Log I/O Error Detected. Shutting down filesystem [ +0.000029] XFS (sdf): Please umount the filesystem and rectify the problem(s) [ +0.000034] XFS (sdf): xfs_log_force: error -5 returned. [ +2.449233] XFS (sdf): xfs_log_force: error -5 returned. [ +4.106773] sd 0:2:5:0: [sdf] Synchronizing SCSI cache [ +25.997287] XFS (sdf): xfs_log_force: error -5 returned. Где sd 0:2:5:0 — это: h == hostadapter id (first one being 0) c == SCSI channel on hostadapter (first one being 2) — он же PCI-слот t == ID (5) — он же номер слота вылетевшего диска l == LUN (first one being 0)
Ресканим:
echo 1 > /sys/block/sdY/device/delete echo "2 5 0" > /sys/class/scsi_host/host0/scan— неправильное имя заменяемого диска. Далее для замены брика нам надо создать новую директорию для монтирования, накатить файловую систему и примонтировать его:где sdY
mkdir -p /export/newvol/brick mkfs.xfs /dev/sdf -f mount /dev/sdf /export/newvol/Выполняем замену brick:
gluster volume replace-brick holodilnik server1:/export/sdf/brick server1:/export/newvol/brick commit force
Запускаем лечение:
gluster volume heal holodilnik full gluster volume heal holodilnik info summaryОтвал арбитра:
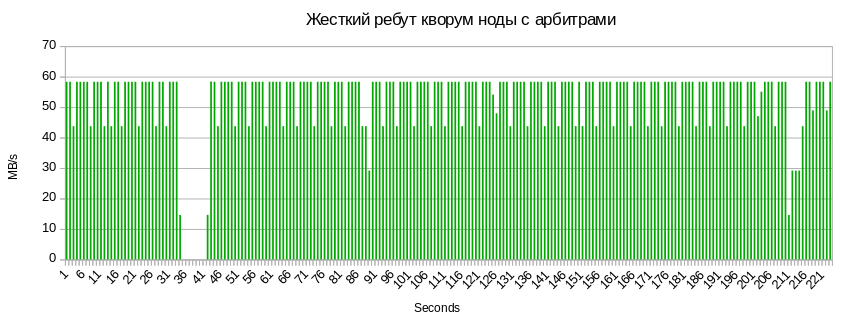 Те же 5–7 секунд недоступности шары и 3 секунды просадки, связанные с синком метаданных на кворум ноду.
Те же 5–7 секунд недоступности шары и 3 секунды просадки, связанные с синком метаданных на кворум ноду.
Резюме
Результаты деструктивных тестов нас порадовали, и мы частично ввели его в прод, но радовались мы недолго...Проблема 1, она же известная бага
При удалении большого количества файлов и директорий (порядка 100 000) мы откушали вот такую «красоту»:
rm -rf /mnt/holodilnik/* rm: cannot remove ‘backups/public’: Remote I/O error rm: cannot remove ‘backups/mongo/5919d69b46e0fb008d23778c/mc.ru-msk’: Directory not empty rm: cannot remove ‘billing/2018-02-02_before-update_0.10.0/mongodb/’: Stale file handleПрочитал около 30 таких заявок, которые начинаются с 2013 года. Решения проблемы нигде нет. Red Hat рекомендует обновить версию, но нам это не помогло. Наш workaround — просто зачищать остатки битых директорий в бриках на всех нодах:
pdsh -w server[1-3] -- rm -rf /export/brick[0-9]/holodilnik/Но дальше — хуже.
Проблема 2, самая страшная
Мы попытались распаковать архив с большим количеством файлов внутри шары Striped вольюма и получили повисший tar xvfz в Uninterruptible sleep. Который лечится только ребутом ноды клиента.
Осознав, что дальше так жить нельзя, мы обратились к последней не испробованной нами конфигурации, которая не вызывала у нас доверия, — erasure coding. Единственная её сложность — в понимании принципа сборки вольюма.
Прогнав все те же самые деструктивные тесты, мы получили те же приятные результаты. Загружали в него миллионы файлов и удаляли. Как только мы ни старались, сломать Dispersed volume у нас не получилось. Мы видели более высокую нагрузку на CPU, но пока для нас это некритично.
Сейчас он бекапит кусок нашей инфраструктуры и используется как файлопомойка для наших внутренних применений. Хотим с ним пожить, посмотреть, как он работает под разной нагрузкой. Пока понятно, что тип вольюмов «страйп» работает странно, а остальные — очень хорошо. Далее в планах — собрать 50 ТБ dispersed volume 4 + 2 на шести серверах с широким Infiniband-каналом, прогнать перфоманс-тесты и продолжать глубже вникать в принципы его работы.

