.svg)



О технологиях
Glusterfs + erasure coding: когда надо много, дешево и надежно
829
14 минут
Содержание:
Гластер в России мало у кого есть, и любой опыт интересен. У нас он большой и промышленный и, судя по дискуссии в прошлом посте, востребованный.
Я рассказывал о самом начале опыта переноса бекапов с Enterprise хранилища на Glusterfs.
Это недостаточно хардкорно. Мы не остановились и решили собрать что-то более серьёзное. Поэтому здесь речь пойдёт о таких вещах, как erasure coding, шардинг, ребалансировка и её троттлинг, нагрузочное тестирование и так далее.
![]()
Это недостаточно хардкорно. Мы не остановились и решили собрать что-то более серьёзное. Поэтому здесь речь пойдёт о таких вещах, как erasure coding, шардинг, ребалансировка и её троттлинг, нагрузочное тестирование и так далее.

- Больше теории волюмы/сабволюмы
- hot spare
- heal / heal full / rebalance
- Выводы после ребута 3 нод (никогда так не делайте)
- Как влияет на нагрузку сабволюма запись с разной скоростью от разных ВМ и shard on/off
- rebalance после вылета диска
- fast rebalance
Что хотели
Задача простая: собрать дешёвый, но надёжный сторадж. Дешёвый насколько можно, надёжный — чтобы не было страшно хранить на нём наши собственные файлы прода. Пока. Потом, после долгих тестов и бекапов на другую систему хранения — ещё и клиентские.
Применение (последовательное IO):
— Бекапы
— Тестовые инфраструктуры
— Тестовое хранилище для тяжёлых медиафайлов.
Мы находимся здесь.
— Боевая файлопомойка и серьёзные тестовые инфраструктуры
— Хранилище для важных данных.
Как и прошлый раз, главное требование — скорость сети между инстансами Гластера. 10G поначалу — нормально.
Применение (последовательное IO):
— Бекапы
— Тестовые инфраструктуры
— Тестовое хранилище для тяжёлых медиафайлов.
Мы находимся здесь.
— Боевая файлопомойка и серьёзные тестовые инфраструктуры
— Хранилище для важных данных.
Как и прошлый раз, главное требование — скорость сети между инстансами Гластера. 10G поначалу — нормально.
Теория: что такое dispersed volume?
Dispersed volume основан на технологии erasure coding (EC), что обеспечивает достаточно эффективную защиту от сбоев дисков или серверов. Это как RAID 5 или 6, но не совсем. Он хранит закодированный фрагмент файла для каждого брика таким образом, что для восстановления файла требуется только подмножество фрагментов, хранящихся на оставшихся бриках. Количество бриков, которые могут быть недоступны без потери доступа к данным, настраивается администратором во время создания тома.
![]()
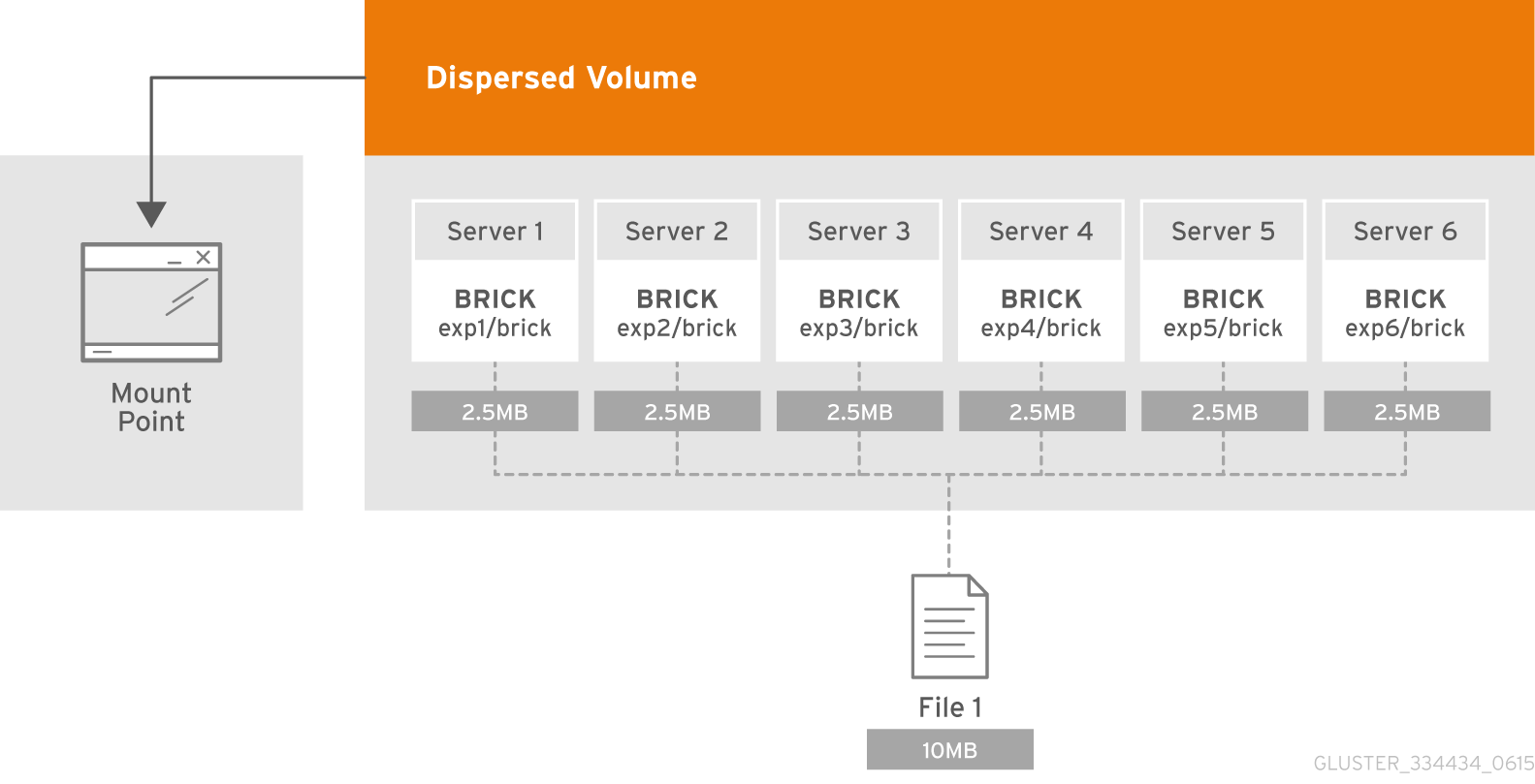
Что такое сабволюм (subvolume)?
Сущность сабволюма в терминологии GlusterFS проявляется вместе с distributed волюмами. В distributed-disperced erasure coding будет работать как раз в рамках сабволюма. А в случае, например, с distributed-replicated данные будут реплицироваться в рамках сабволюма.
Каждый из них разнесён на разные сервера, что позволяет их свободно терять или выводить на синк. На рисунке зелёным отмечены сервера (физические), пунктиром — сабволюмы. Каждый из них представлен как диск (том) серверу приложений:
![]()
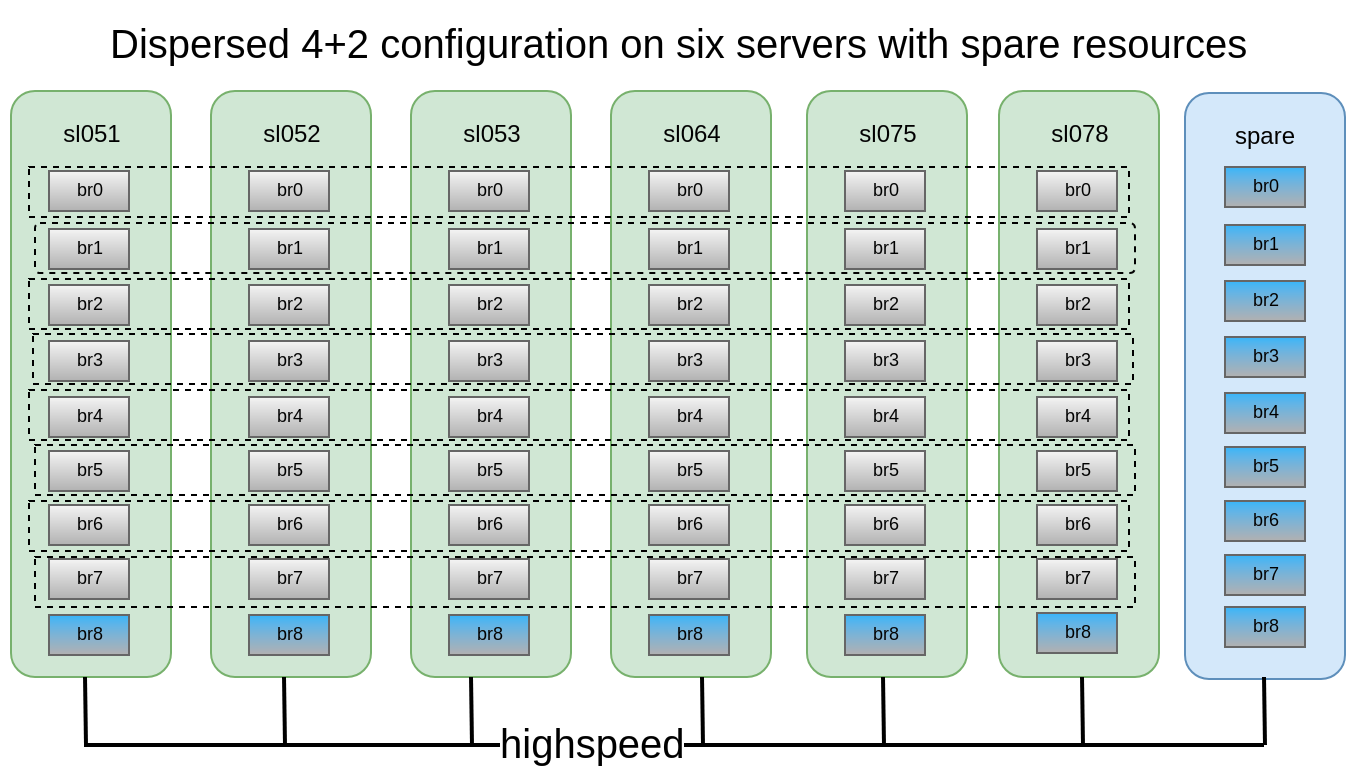
Было решено, что конфигурация distributed-dispersed 4+2 на 6 нодах выглядит достаточно надежно, мы можем потерять 2 любых сервера или по 2 диска в рамках каждого сабволюма, продолжая иметь доступ к данным.
В нашем распоряжении было 6 стареньких DELL PowerEdge R510 с 12 дисковыми слотами и 48x2ТБ 3.5 SATA дисков. В принципе, если есть сервера с 12 дисковыми слотами, и имея на рынке диски до 12тб мы можем собрать хранилку размером до 576тб полезного пространства. Но не забывайте, что хоть максимальные размеры HDD продолжают из года в год расти, их производительность стоит на месте и ребилд диска размером 10-12ТБ может занять у вас неделю.
![]()
Создание волюма:
Подробное описание, как подготавливать брики, вы можете прочитать в моём предыдущем посте
Создаем, но не спешим запускать и монтировать, так как нам еще придется применить несколько важных параметров.
Каждый из них разнесён на разные сервера, что позволяет их свободно терять или выводить на синк. На рисунке зелёным отмечены сервера (физические), пунктиром — сабволюмы. Каждый из них представлен как диск (том) серверу приложений:

Было решено, что конфигурация distributed-dispersed 4+2 на 6 нодах выглядит достаточно надежно, мы можем потерять 2 любых сервера или по 2 диска в рамках каждого сабволюма, продолжая иметь доступ к данным.
В нашем распоряжении было 6 стареньких DELL PowerEdge R510 с 12 дисковыми слотами и 48x2ТБ 3.5 SATA дисков. В принципе, если есть сервера с 12 дисковыми слотами, и имея на рынке диски до 12тб мы можем собрать хранилку размером до 576тб полезного пространства. Но не забывайте, что хоть максимальные размеры HDD продолжают из года в год расти, их производительность стоит на месте и ребилд диска размером 10-12ТБ может занять у вас неделю.

Создание волюма:
Подробное описание, как подготавливать брики, вы можете прочитать в моём предыдущем посте
gluster volume create freezer disperse-data 4 redundancy 2 transport tcp \ $(for i in {0..7} ; do echo {sl051s,sl052s,sl053s,sl064s,sl075s,sl078s}:/export/brick$i/freezer ; done)
Создаем, но не спешим запускать и монтировать, так как нам еще придется применить несколько важных параметров.
Что мы получили
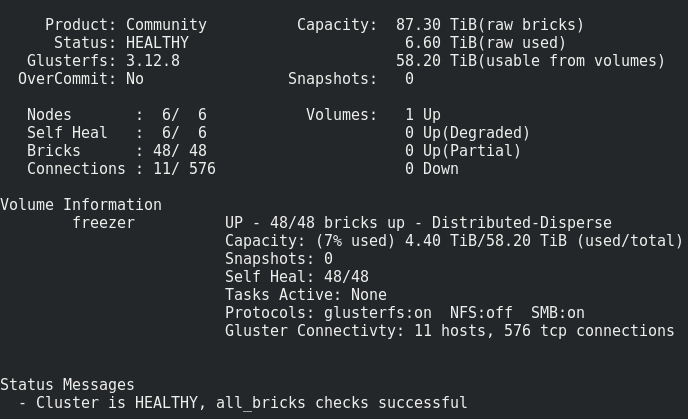
Всё выглядит вполне нормально, но есть один нюанс.
Он заключается в записи на брики такого волюма:
Файлы кладутся поочерёдно в сабволюмы, а не равномерно размазываются по ним, следовательно, рано или поздно мы упрёмся в его размер, а не в размер всего волюма. Максимальный размер файла, который мы можем положить в это хранилище, = полезный размер сабволюма минус уже занятое на нём пространство. В моем случае это < 8 Тб.
Что же делать? Как же быть?
Эту проблему решает шардинг или страйп вольюм, но, как показала практика, страйп работает из рук вон плохо.
Поэтому будем пробовать шардинг.
Что такое шардинг, подробно тут.
Что такое шардинг, коротко:
Каждый файл, который вы кладёте в волюм, будет разделён на части (шарды), которые относительно равномерно раскладываются по сабволюмам. Размер шарда указывается администратором, стандартное значение 4 МБ.
Включаем шардинг после создания волюма, но до того как стартовали его:
gluster volume set freezer features.shard on
Выставляем размер шарда (какой оптимальный? Чуваки из oVirt рекомендуют 512MB):
gluster volume set freezer features.shard-block-size 512MB
Опытным путём выясняется, что фактический размер шарда в брике при использовании dispersed волюма 4 + 2 получается равен shard-block-size/4, в нашем случае 512M/4 = 128M.
Каждый шард по логике erasure coding раскладывается по брикам в рамках сабволюма вот такими кусками: 4*128M+2*128M
Нарисовать кейсы отказов, которые переживает gluster этой конфигурации:
В данной конфигурации мы можем пережить падение 2 нод или 2 любых дисков в рамках одного сабволюма.
Для тестов мы решили подсунуть получившуюся хранилку под наше облако и запускать fio с виртуальных машин.
Включаем последовательную запись с 15 ВМ и делаем следующее.
Ребут 1-й ноды:
17:09
Выглядит некритично (~5 секунд недоступности по параметру ping.timeout).
17:19
Запустил heal full.
Количество heal entries только растёт, вероятно, из-за большого уровня записи на кластер.
17:32
Решено выключить запись с ВМ.
Количество heal entries начало уменьшаться.
17:50
heal выполнен.
Ребут 2 нод:
Наблюдаются такие же результаты, что и с 1-й нодой.
Ребут 3 нод:
Точка монтирования выдала Transport endpoint is not connected, ВМ получили ioerror.
После включения нод Гластер восстановился сам, без вмешательства с нашей стороны, и начался процесс лечения.
Но 4 из 15 ВМ не смогли подняться. Увидел ошибки на гипервизоре:
2018.04.27 13:21:32.719 ( volumes.py:0029): I: Attaching volume vol-BA3A1BE1 (/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1) with attach type generic... 2018.04.27 13:21:32.721 ( qmp.py:0166): D: Querying QEMU: __com.redhat_drive_add({'file': u'/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1', 'iops_rd': 400, 'media': 'disk', 'format': 'qcow2', 'cache': 'none', 'detect-zeroes': 'unmap', 'id': 'qdev_1k7EzY85TIWm6-gTBorE3Q', 'iops_wr': 400, 'discard': 'unmap'})... 2018.04.27 13:21:32.784 ( instance.py:0298): E: Failed to attach volume vol-BA3A1BE1 to the instance: Device 'qdev_1k7EzY85TIWm6-gTBorE3Q' could not be initialized Traceback (most recent call last): File "/usr/lib64/python2.7/site-packages/ic/instance.py", line 292, in emulation_started c2.qemu.volumes.attach(controller.qemu(), device) File "/usr/lib64/python2.7/site-packages/c2/qemu/volumes.py", line 36, in attach c2.qemu.query(qemu, drive_meth, drive_args) File "/usr/lib64/python2.7/site-packages/c2/qemu/_init_.py", line 247, in query return c2.qemu.qmp.query(qemu.pending_messages, qemu.qmp_socket, command, args, suppress_logging) File "/usr/lib64/python2.7/site-packages/c2/qemu/qmp.py", line 194, in query message["error"].get("desc", "Unknown error") QmpError: Device 'qdev_1k7EzY85TIWm6-gTBorE3Q' could not be initialized qemu-img: Could not open '/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1': Could not read image for determining its format: Input/output error
Жестко погасить 3 ноды с выключенным шардингом
Transport endpoint is not connected (107) /GLU/volumes/e0/e0bf9a42-8915-48f7-b509-2f6dd3f17549: ERROR: cannot read (Input/output error)
Тоже теряем данные, восстановить не получается.
Мягко погасить 3 ноды c шардингом, будет ли data corruption?
Есть, но значительно меньше (совпадение?), потерял 3 диска из 30.
Выводы:
- Heal этих файлов висит бесконечно, rebalance не помогает. Приходим к выводу, что файлы, на которые в момент выключения 3-й ноды шла активная запись, потеряны безвозвратно.
- Никогда не перезагружайте больше 2 нод в конфигурации 4 + 2 в продуктиве!
- Как не потерять данные, если очень хочется ребутнуть 3 + ноды? П рекратить запись в точку монтирования и/или остановить volume.
- Замену ноды или брика надо производить как можно скорее. Для этого крайне желательно иметь, например, по 1–2 а-ля hot-spare брика в каждой ноде для быстрой замены. И ещё одну запасную ноду с бриками на случай отвала ноды.
Также очень важно протестировать случаи замены дисков
Вылеты бриков (дисков):
17:20
Выбиваем брик:
/dev/sdh 1.9T 598G 1.3T 33% /export/brick6
17:22
gluster volume replace-brick freezer sl051s:/export/brick_spare_1/freezer sl051s:/export/brick2/freezer commit force
Видно вот такую просадку в момент замены брика (запись с 1 источника):

Процесс замены достаточно долгий, при небольшом уровне записи на кластер и дефолтных настройках 1 Тб лечится около суток.
Регулируемые параметры для лечения:
gluster volume set cluster.background-self-heal-count 20 # Default Value: 8 # Description: This specifies the number of per client self-heal jobs that can perform parallel heals in the background. gluster volume set cluster.heal-timeout 500 # Default Value: 600 # Description: time interval for checking the need to self-heal in self-heal-daemon gluster volume set cluster.self-heal-window-size 2 # Default Value: 1 # Description: Maximum number blocks per file for which self-heal process would be applied simultaneously. gluster volume set cluster.data-self-heal-algorithm diff # Default Value: (null) # Description: Select between "full", "diff". The "full" algorithm copies the entire file from source to # sink. The "diff" algorithm copies to sink only those blocks whose checksums don't match with those of # source. If no option is configured the option is chosen dynamically as follows: If the file does not exist # on one of the sinks or empty file exists or if the source file size is about the same as page size the # entire file will be read and written i.e "full" algo, otherwise "diff" algo is chosen. gluster volume set cluster.self-heal-readdir-size 2KB # Default Value: 1KB # Description: readdirp size for performing entry self-heal
Option: disperse.background-heals
Default Value: 8
Description: This option can be used to control number of parallel heals
Option: disperse.heal-wait-qlength
Default Value: 128
Description: This option can be used to control number of heals that can wait
Option: disperse.shd-max-threads
Default Value: 1
Description: Maximum number of parallel heals SHD can do per local brick. This can substantially lower heal times, but can also crush your bricks if you don't have the storage hardware to support this.
Option: disperse.shd-wait-qlength
Default Value: 1024
Description: This option can be used to control number of heals that can wait in SHD per subvolume
Option: disperse.cpu-extensions
Default Value: auto
Description: force the cpu extensions to be used to accelerate the galois field computations.
Option: disperse.self-heal-window-size
Default Value: 1
Description: Maximum number blocks(128KB) per file for which self-heal process would be applied simultaneously.
Выстаил:
disperse.shd-max-threads: 6 disperse.self-heal-window-size: 4 cluster.self-heal-readdir-size: 2KB cluster.data-self-heal-algorithm: diff cluster.self-heal-window-size: 2 cluster.heal-timeout: 500 cluster.background-self-heal-count: 20 cluster.disperse-self-heal-daemon: enable disperse.background-heals: 18
С новыми параметрами 1 Тб данных отребилдилось за 8 часов (в 3 раза быстрее!)
Неприятный момент, что в результате получается брик большего размера, чем был
был:
Filesystem Size Used Avail Use% Mounted on /dev/sdd 1.9T 645G 1.2T 35% /export/brick2
стал:
Filesystem Size Used Avail Use% Mounted on /dev/sdj 1.9T 1019G 843G 55% /export/hot_spare_brick_0
Надо разбираться. Вероятно, дело в надувании тонких дисков. При последующей замене увеличившегося брика размер остался прежним.
Ребалансировка:
After expanding or shrinking (without migrating data) a volume (using the add-brick and remove-brick commands respectively), you need to rebalance the data among the servers. In a non-replicated volume, all bricks should be up to perform replace brick operation (start option). In a replicated volume, at least one of the brick in the replica should be up.
Шейпинг ребалансировки:
Option: cluster.rebal-throttle
Default Value: normal
Description: Sets the maximum number of parallel file migrations allowed on a node during the rebalance operation. The default value is normal and allows a max of [($(processing units) — 4) / 2), 2] files to b
e migrated at a time. Lazy will allow only one file to be migrated at a time and aggressive will allow max of [($(processing units) — 4) / 2), 4]
Option: cluster.lock-migration
Default Value: off
Description: If enabled this feature will migrate the posix locks associated with a file during rebalance
Option: cluster.weighted-rebalance
Default Value: on
Description: When enabled, files will be allocated to bricks with a probability proportional to their size. Otherwise, all bricks will have the same probability (legacy behavior).
Сравнение записи, а потом чтения теми же параметрами fio (более подробные результаты performance тестов — в личку):
fio --fallocate=keep --ioengine=libaio --direct=1 --buffered=0 --iodepth=1 --bs=64k --name=test --rw=write/read --filename=/dev/vdb --runtime=6000



Если интересно — сравнение скорости rsync к трафику на ноды Гластера:
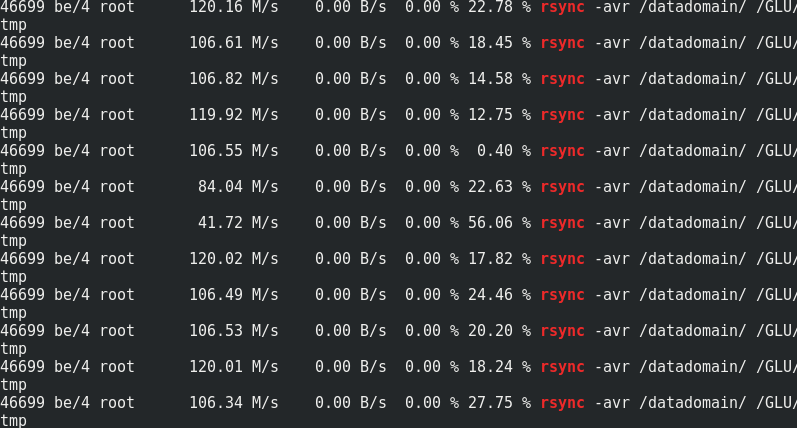

Видно, что примерно 170 МБ/сек/ трафика к 110 МБ/сек/ полезных данных. Выходит, это 33% дополнительного трафика, как и 1/3 избыточности Erasure Coding.
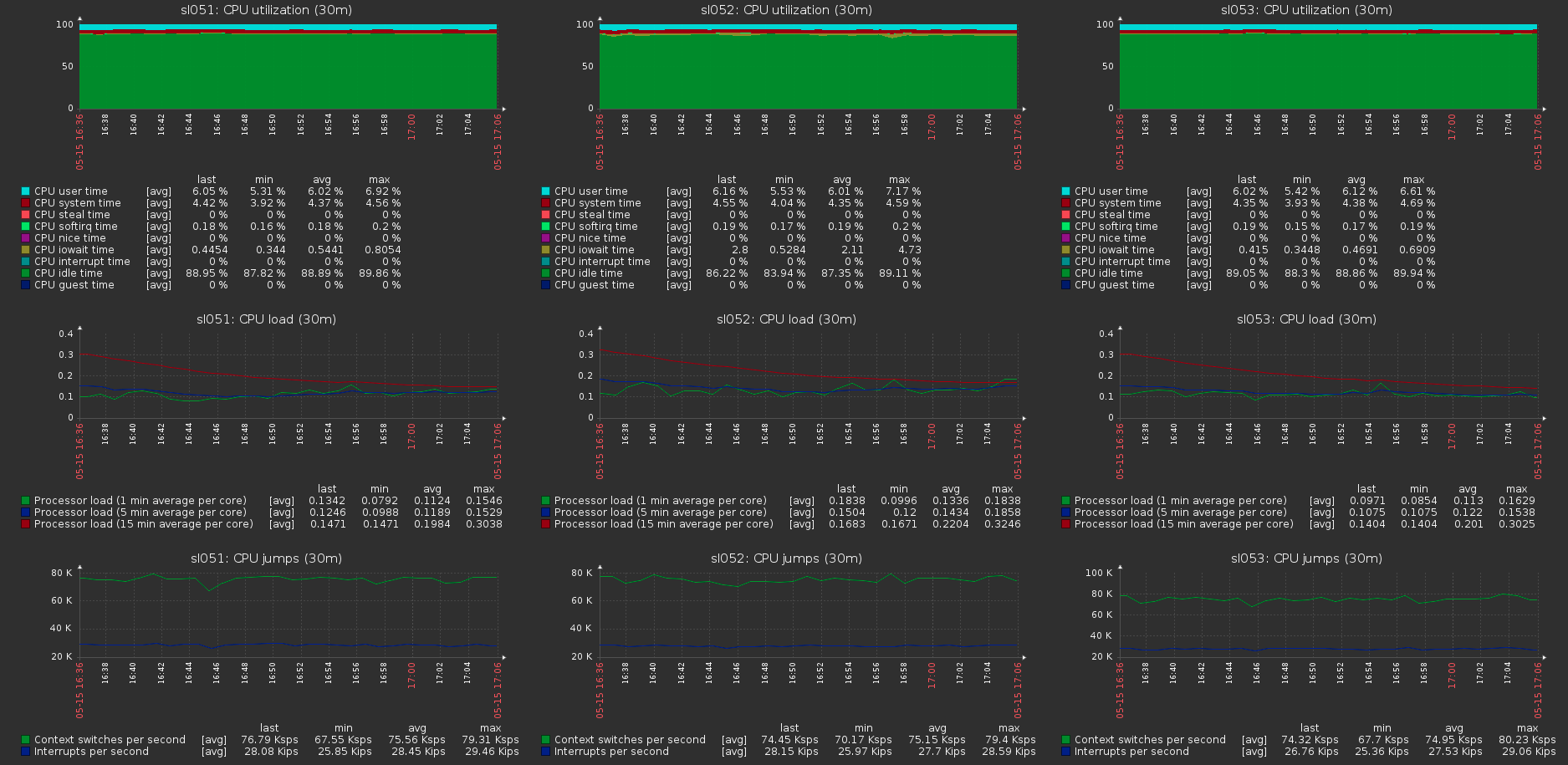
Потребление памяти на серверной стороне с нагрузкой и почти без неё не меняется:
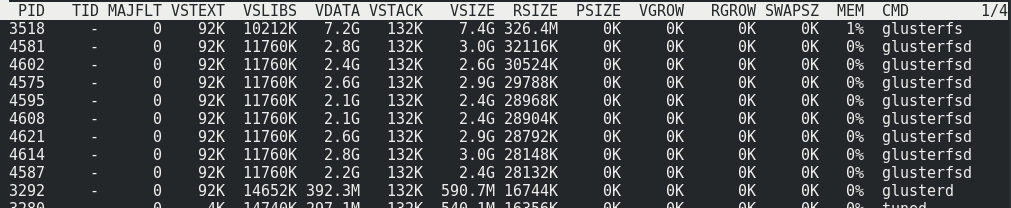
Нагрузка на хосты кластера при максимальной нагрузке на вольюм: